Clive Boulton: Whole Chain Traceability, pulling a Kobayshi Maru
A little background information about how this presentation came to be ....
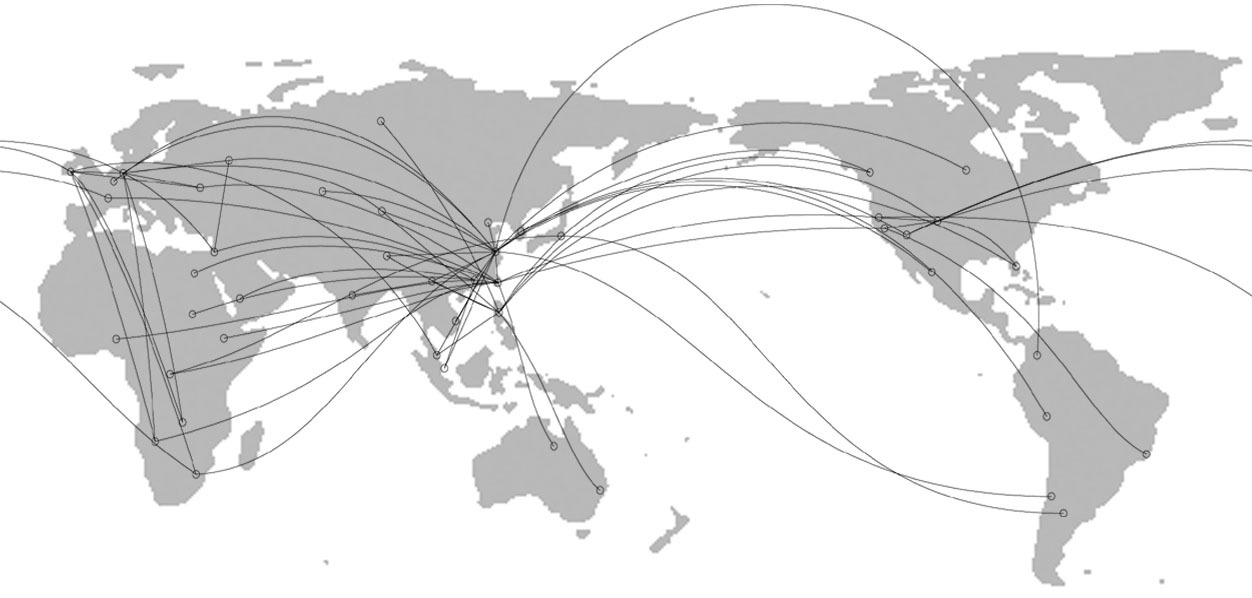
Clive Boulton made this timely, impressive presentation at a luncheon held in Stillwater, Oklahoma on 6 January 2012. Stillwater is where Oklahoma State University - lead research institution of the Whole Chain Traceability Consortium - is located. The pathway to Stillwater from the Seattle area began with the CCNx conference held at the Palo Alto Research Center in September, 2011. I attended CCNxCon to make one or more connections relevant to the Whole Chain Traceability Consortium. Clive wasn't physically at the conference but he was looking in from north of Seattle via a live audio/video stream. Clive heard me asking a question from the audience about possibly applying CCN to supply chain traceability needs in food safety. Like me, Cliive has a passion for food traceability and so he tweeted "Who's that?" to one of the CCNxCon managers. A Twitter introduction was made.
Clive is currently a co-organizer of the Seattle Google Technology User Group at GTUG - http://www.meetup.com/seattle-gtug. He has a "finger on the pulse" of technology developments in Seattle and Silicon Valley which he commonly blogs about at http://cliveboulton.com/. And Clive has specially blogged there about Pardalis' Common Point Authoring at http://cliveboulton.com/post/12071791931/pardalis-is-banking-on-granular-information.
Clive is particularly interested in enterprise connected consumer solutions at web scale with polyglot technologies. Clive has opinions on how MSFT SQL Azure (or other "Big Data" databases) may be horizontally sharded (i.e., partitioned) with immutable informational objects for massive scalability. He is also very knowledgeable of the need to balance scalability against inherent latency issues that may result, for instance, in slow consumer access via mobile devices. And he has practical ideas about how to syngergistically leverage the resources and relationships of the Whole Chain Traceability Consortium for fostering an ecosystem of API development.
As a result of his visit to Stillwater, I am pleased announce that Clive will be serving as a consultant to the Whole Chain Traceability Consortium a/k/a @WholeChainTrace. This should make for a potent connection between the #CollabEnt (i.e., collaboration enterprise) of Clive's 20th slide and the increasingly critical need for real-time food traceability. Stay tuned.
 Steve Holcombe
Steve Holcombe
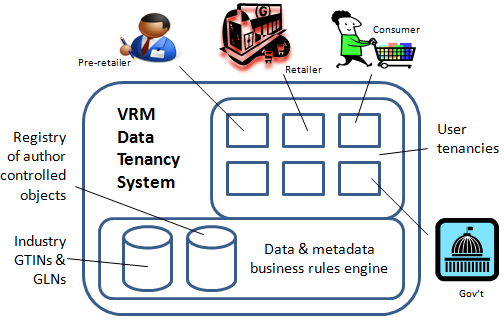
New Slide 19 by @iC - #Cloud Application: Partnership model for a neutral #traceability database | http://www.slideshare.net/clibou/wctcevolution