Beyond The Tipping Point: Interoperable Exchange of Provenance Data
Introduction
 This is our fourth "tipping point" publication.
This is our fourth "tipping point" publication.
The first was The Tipping Point Has Arrived: Trust and Provenance in Web Communications. We highlighted there the significance of the roadmap laid out by the Wikidata Project - in conjunction with the W3C Provenance Working Group - to provide trust and provenance in its form of web communications. We were excited by proposals to granularize single facts, and to immutabilize the data elements to which those facts are linked. We opined this to be critical for trust and provenance in whole chain communications. But at that time, the Wikidata Project was still waiting on the W3C Provenance Working Group to establish the relevant standards. No longer is this the case.
The second post was The Tipping Point Has Arrived: Market Incentives for Selective Sharing in Web Communications. We there emphasized the emerging market-based opportunities for information sharing between enterprises and consumers. We were particularly impressed with Google’s definition of "selective sharing" (made with GooglePlus in mind) to include controls for overcoming both over-sharing and fear of sharing by information producers. Our fourth post, below, includes a similar discussion but is this time skewed relative to the increasing needs for data interoperability among web-based file hosting services in the Cloud.
The third post - Why Google Must - And Will - Drive NextGen Social for Enterprises - introduced common point social networking which we defined as providing the means and functions for the creation and versioning of immutable data elements at a single location. Github was pointed to as a comparative but we proposed that Google would lead in introducing common point networking (or similar) with a roadmap of means and functions it was already backing in the Wikidata Project. We identified an inviting space for common point social networking between Google's Knowledge Graph and emerging GS1 (i.e., enterprise) standards for Key Data Elements (KDEs). We identified navigational search for selectively shared proprietary information (like provenance information) as a business model in support.
This fourth post posits the accessibility of data elements (like KDEs) from web-based data hosting services in the Cloud providing content-addressable storage. This is a particularly interesting approach in the wake of the recent revelations regarding PRISM, the controversial surveillance program of the U.S. National Security Agency. The NSA developed their Apache Accumulo NoSQL datastore based on Google's BigTable data model but with cell-level security controls. Ironically, those kind of controls allow for tagging of a data object with security labels for selective sharing. This kind of tagging of a data object within a data set represents a paradigm shift toward common point social networking (or the distributed social networking envisioned by Google's Camlistore as described below).
The PROV Ontology
The W3C Provenance Working Group published its PROV Ontology on 30 April 2013 in the form of "An Overview of the PROV Family of Documents". The PROV family of documents define "a model, corresponding serializations and other supporting definitions to enable the inter-operable interchange of provenance information in heterogeneous environments such as the Web."
The W3C recommends that a provenance framework should support these 8 characteristics:
-
the core concepts of identifying an object, attributing the object to person or entity, and representing processing steps;
-
accessing provenance-related information expressed in other standards;
-
accessing provenance;
-
the provenance of provenance;
-
reproducibility;
-
versioning;
-
representing procedures; and
-
representing derivation.
These 8 recommendations are more specifically addressed at 7.1 of the W3C Incubator Group Report 08 December 2010. In effect, the W3C Provenance Working Group has now established the relevant standards for exporting (or importing) trust and provenance information about the facts in Wikidata.
As we observed in our first tipping point, the Wikidata Project was first addressing the deposit by content providers of data elements (e.g., someone's birth date) at a single, fixed location for supporting the semantic relationships that Wikipedia users are seeking. The export of granularized provenance information about Wikidata facts was on their wish list. Now the framework for making that wish come true has been established. Again, the key aspect for us about the Wikidata Project is that it shouldn’t matter - from the standpoint of provenance - how the accessed data at that fixed location is exchanged or transported, whether via XML meta-data, JSON documents or other. But the fixing of the location for the granularized data provides a critical authentifying reference point within a provenance framework.
Interoperably Connecting Wikidata to Freebase/Knowledge Graph
On 14 June 2013 Shawn Simister, Knowledge Developer Relations for Google, offered the following to the Discussion list for the Wikidata project:
"Would the WikiData community be interested in linking together Wikidata pages with Freebase entities? I've proposed a new property to link the two datasets .... Freebase already has interwiki links for many entities so it wouldn't be too hard to automatically determine the corresponding Wikidata pages. This would allow people to mash up both datasets and cross-reference facts more easily."
Later on in the conversation thread with Maximilian Klein, Wikpedian in Residence, Simister also added "we currently extract a lot of data from [Wikidata Project] infoboxes and load that data into Freebase which eventually makes its way into the Knowledge Graph so [interoperably] linking the two datasets would make it easier for us to extract similar data from WikiData in the future."
See the discussion thread at http://lists.wikimedia.org/pipermail/wikidata-l/2013-June/002359.html
This is non-trivial conversation between agents of Google and Wikipedia about interoperably sharing and synchronizing data between two of the largest data sets in the world. But we believe that the marketplace for introducing provenance frameworks is to be found among the data sets of file hosting and storage services in the Cloud.
The Rise Of File Sharing In The Cloud
Check out the comparison of file hosting and storage services (with file sharing possibility) at http://en.wikipedia.org/wiki/Comparison_of_file_hosting_services. Identified file storage services include Google Drive, Dropbox, IBM SmartCloud Connections, DocLanding and others. All provide degrees of collaborative and distributed access to files stored in the Cloud. New and emerging services include allowing users to perform the same activities across all sorts of devices which will require similar sharing and synchronization of data across all devices. This has huge ramifications for not just the sharing of personal data in the Cloud, but also for the sharing of proprietary, enterprise data. And when one is talking about proprietary information, one has to consider the introduction of a provenance framework.
The Next Logical Step: Content-addressable Storage In the Cloud
"Content-addressable storage ... is a mechanism for storing information that can be retrieved based on its content, not its storage location. It is typically used for high-speed storage and retrieval of fixed content, such as documents stored for compliance with government regulations." Github is an example that we mentioned in our third tipping point blog. CCNx (discussed a little later) is another example. Camlistore, a Google 20 Percent Time Project, while still in its infancy, is yet another example.
"Camlistore can represent both immutable information (like snapshots of file system trees), but can also represent mutable information. Mutable information is represented by storing immutable, timestamped, GPG-signed blobs representing a mutation request. The current state of an object is just the application of all mutation blobs up until that point in time. Thus all history is recorded and you can look at an object as it existed at any point in time, just by ignoring mutations after a certain point."
Camilstore has only revealed they are handling sharing similarly to Github. But NSA's Apache Accumulo - and a spinoff called Sqrrl - may currently be the only NoSQL solutions with cell-level security controls. Sqrrl, a startup that is comprised of former members of the NSA Apache Accumulo team, is commercially providing an extended version of Apache Accumulo with cell-level security features. Co-founder Ely Kahn of Sqrrl says, "We're essentially creating a premium grade version of Accumulo with additional analysis, data ingest, and security features, and taking a lot of the lessons learned from working in large environments." We suspect that Camlistore is similarly using security tags (though we can’t say for sure because it is a newly emerged feature not covered in Camlistore's documentation). Camlistore calls what is doing as decentralized social networking. This kind of activity (and more, below) gives us increasing reason to expect that content-addressable products will arise to break the silos of supply chains.
Surveying the Field
Global trade is a series of discrete transactions between buyers and sellers. It is generally difficult – if not impossible – to determine a clear picture of the entire lifecycle of products. The proprietary data assets (including provenance data) of enterprises large and small have commonly not been shared for two essential reasons:
- the lack of tools for selective sharing, and
- the fear of sharing offered under "all or nothing" social transparency sharing models.
We believe that with the introduction of content-addressable storage in the Cloud there will occur a paradigm shift toward the availability of tools for selective sharing among people and their devices. In that context it would be interesting to see the new activities and efforts of Wikidata, Github, Camlistore and Sqrrl connected with the already existing activities and efforts made in supply chains.
Ward Cunningham, inventor of the wiki, formerly Nike’s first Code for a Better World Fellow, and now Staff Engineer at New Relic, has innovated a paragraph level wiki for curating sustainability data. Ward shows how data and visualization plugins could serve the needs of organizations sharing material sustainability data. Cunningham’s visualization, below, once paired with content-addressable storage, simplifies greater authenticity and relevancy within the enterprise.
Leonardo Bonanni started SourceMap as his Ph.D. thesis project at the MIT Media Lab. Sourcemap’s inspiring visualizations are crowdsourced from all over the world to transparently show "where stuff comes from". Again, SourceMap, when paired with content-addressable storage, simplifies selective sharing in the cloud.
There is an evolution of innovation spurring new domain specific solutions. We've put together the following table to emphasize the technologies that we find of interest. The table represents a progression toward solving under-sharing in supply chains with content-addressable storage in the Cloud. Entities in the table below are not specially focused on supply chains and but some are thinking about supply chains. No matter. We are attempting to join the dots looking forward based on a progression of granular sharing technologies (i.e., revision control, named data networking, informational objects).
|
product |
wikidata |
git |
sqrrl |
CCNx |
smallest federated wiki |
pardalis |
camlistore |
|
creator and or sponsor notes |
google, paul allen, gordon moore |
git by linus torvalds |
extends nsa security design to enterprise |
parc, named data networking |
wiki inventor ward cunningham |
holcombe, boulton, whole chain traceability consortium |
20 pct project |
|
user experience |
public human machine editable |
revision control, social coding software |
tagged security labels |
federates content efficiently avoiding congestion |
wiki like git paragraph forking |
sharing, traceability, provenance |
personal data storage system for life |
|
selective sharing |
hub data source |
public / private |
authorization systems |
public by default |
merging like github |
hub data access |
private by default |
|
content addressable storage |
xml api |
32-bit unix hashing |
cell level security |
content verifiable from the data itself |
paragraph blobs |
CCNx like informational objects |
github-like json blobs, no meta data |
|
database |
mysql |
above storage |
apache accumulo nosql |
above storage |
couchdb, leveldb |
above storage |
sqlite, mongodb, mysql, postgres, (appengine) |
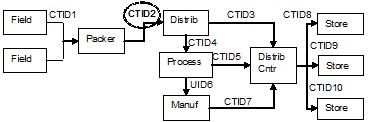
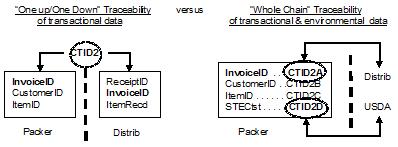
We'd like to take this opportunity to make special mention of the CCNx (Content-centric Networking) Project at PARC begun by Van Jacobson. The first CCNxCon of the CNNx Project is what brought us - Holcombe and Boulton - together. We were both fascinated with prospects of applying CCNx to the length of enterprise supply chains. In fact, the first ever "whole chain traceability" funding from the USDA came in 2011 in no small part because author Holcombe - as the catalyzer of the Whole Chain Traceability Consortium - proposed to extend Pardalis' engineered layer of granular access controls using a content-centric networking data framework. It was successfully proposed to the USDA that the primary benefit of CCNx lay in its ability to retrieve data objects based on what the user wanted, instead of where the data was located. We perceive this even now to be critical to smoothing out the ridges of the "bullwhip effect" in supply chains.
Interoperability, Content-addressable storage and Provenance
Stonebraker et al. postulated the "The End of an Architectural Era (It's Time for a Complete Rewrite)" in 2007 by stating the hypothesis that traditional database management systems are no longer able to represent the holistic answer with respect to the variety of different requirements. Specialized systems will emerge for specific problems. The NoSQL movement made this happen with databases. Google (and Amazon) inspired the NoSQL movement underpinning Cloud storage databases. Nearly all enterprise application startups are now using NoSQL to build datastores at scale to the exclusion of SQL databases. The Oracle/Salesforce/Microsoft partnership announcement in late June, 2013, is well framed by the rise of NoSQL, too. Now we are seeing this begin to happen with an introduced layer of content-addressable storage leading to interoperable provenance.
In our third tipping point blog, we opined that Google must drive nextgen social for enterprises to overcome the bullwhip effects of supply chains. Google has been laying a solid foundation for doing so by co-funding the Wikidata Project, proposing the integration of Wikidata and Knowledge Graph/Freebase, nurturing navigational search as a business model, and gaining keen insights into selective sharing with Google Plus (and the defunct Google Affiliate Network). Call it common point social networking. Call it decentralized social networking. Call it whatever you want to. The tide is rising toward "the inter-operable interchange of provenance information in heterogeneous environments."
Is the siloed internet ever to be cracked? Well, it is safe to say that the NSA has already cracked the data silos of U.S. security agencies with its version of NoSQL Apache Accumulo (again, based on Google's BigData table model). Whatever your feelings or political views about surveillance by the NSA (or Google), it is an historical achievement. Now, outside of government surveillance programs, web-based file sharing is just beginning to shift toward content-addressable data storage and sharing in the Cloud. That holds forth tremendous promise for cracking the silos holding both consumer and enterprise data. There are very interesting opportunities for establishing "first mover" expectations in the marketplace for content-addressable access controls in the Cloud.
The future is here. It is an interoperable future. It is a content-addressable future. And when information needs to be selectively shared (to be shared at all), the future is also about the interoperable exchange of provenance data. Carpe diem.
_______________________________
Authors:
 Steve Holcombe
Steve Holcombe
Pardalis Inc.
 Clive Boulton
Clive Boulton
Independent Product Designer for the Enterprise Cloud
LinkedIn Profile
 Steve Holcombe
Steve Holcombe
Accumulo Secret to Real-time Performance | Published on 7/15/2013 | Sqrrl Co-Founder and CTO Adam Fuchs explains in this whiteboard session how Accumulo provides granular and scaleable security to noSQL database environments in this session with Wikibon's Dave Vellante | http://www.youtube.com/watch?v=5RPaDzOwqQ8