Preface
 This is our third "tipping point" publication.
This is our third "tipping point" publication.
The first was The Tipping Point Has Arrived: Trust and Provenance in Web Communications. We highlighted there the significance of the roadmap laid out by the Wikidata Project. It was our opinion that:
"[a]s the Wikidata Project begins to provide trust and provenance in its form of web communications, they will not just be granularizing single facts but also immutabilizing the data elements to which those facts are linked so that even the content providers of those data elements cannot change them. This is critical for trust and provenance in whole chain communications between supply chain participants who have never directly interacted."
The second post was The Tipping Point Has Arrived: Market Incentives for Selective Sharing in Web Communications. We there emphasized the emerging market-based opportunities for information sharing between enterprises and consumers:
"We know this is a big idea but in our opinion the dynamic blending of Google+ and the Google Affiliate Network could over time bring within reach a holy grail in web communications – the cracking of the data silos of enterprise class supply chains for increased sharing with consumers of what to-date has been "off limits" proprietary product information."
Introducing Common Point Social Networking
For the purposes of this post we introduce and define Common Point Social Networking:
Common point social networking provides the means and functions for the creation and versioning of immutable data elements at a single location by an end-user or a machine which data elements are accessible, linkable and otherwise usable with meta-data authorizations.
The software developers reading this post may recognize similarities with Github. Github is perhaps the canonical proxy for fixed, common point sharing adoption. Software developers publish open source software development projects, providing source code distribution and means for others to contribute changes to the source code back to a common repository. Version control provides a code level audit trail.
In July 2012 Github took a $100M venture capital investment from Andreessen Horowitz. There’s no doubt that some of this funding will be used by Github to compete in the enterprise space. But we further offer here that Google is better positioned to lead the current providers of enterprise software and cloud services in introducing a new generation of online social networks in the fertile ground between enterprises and consumers. We propose that Google so lead by introducing and/or further encouraging a roadmap of means and functions it is already backing in the Wikidata Project. We have identified an inviting space for common point social networking to serve as a bridge between Google's Knowledge Graph and the emerging GS1 standards for Key Data Elements (KDEs).
A Sea Change in Understanding
In 2012 there was a sea change in understanding that greater access to proprietary enterprise data is necessary for creating new business models between enterprises and consumers. Yet there remains confusion on how to do so. There is much rhetorical cross-over these days between the social networking of "personal data" and "enterprise data" but enterprise data is - and will long remain - different from personal data. Again, in our opinion, enterprise data is overwhelmingly a proprietary asset that must be selectively accessed at a granular level from a fixed, common point to have any chance of being efficiently shared.
GS1 and Whole Chain Traceability
From 2010 through 2011, Pardalis Inc. catalyzed a successful research funding strategy in a series of “whole chain traceability” funding submissions seeking to employ the use of granular, immutable data elements in networked communications.[1] The computer networking aspects of this food supply chain research was based upon a granularization of critical tracking events (CTEs) with a high-level derivation of Pardalis’ patented processes for registering immutable data elements and their informational objects at a fixed location with meta-data authorizations. See Whole Chain Traceability: A Successful Research Funding Strategy. At the solicitation of co-author Holcombe, GS1 gave an early letter of support to this process, and GS1 was subsequently kept “in the loop”, too. This successful research funding strategy has from all appearances subsequently been given a favorable nod by GS1 in one of its recent publications, Achieving Whole Chain Traceability in the U.S. Food Supply Chain - How GS1 Standards make it possible. Here’s an excerpt -
"To achieve whole chain traceability, trading partners must be able to link products with locations and times through the supply chain. For this purpose, the work led by the Institute of Food Technologists described two foundational concepts: Critical Tracking Events (CTEs) and Key Data Elements (KDEs). With GS1 Standards as a foundation, communicating CTEs and KDEs is achievable."
So who is GS1, you ask? GS1 is "the international not-for-profit association dedicated to the development and implementation of global standards and solutions to improve the efficiency and visibility of supply and demand chains globally and across multiple sectors." You know that unique barcode symbology you see on the products you purchase? That barcode is standardized by GS1 and may include KDEs.
We applaud the introduction of KDEs by GS1. The inclusion of KDEs is a necessary step for moving beyond the lugubrious one-up/one-down information sharing that is overwhelmingly prevalent in today’s enterprise supply chains. Enterprises have long been comfortable with one-up/one-down pushing generic products down the chain. But it is a mode of information sharing that doesn’t fit well at all into today’s consumer demand chains that desire to pull real-time, trustworthy information. Furthermore, one-up/one-down information sharing significantly contributes to the "bullwhip effect" within supply chains that cost enterprises in a number of ways as explained in more detail in The Bullwhip Effect:
"The challenge is not one of fixing the latest privacy control issue that Facebook presents to us. Nor is the challenge fixed with an application programming interface for integrating Salesforce.com with Facebook. The challenge is in providing the software, tools and functionalities for the discovery in real-time of proprietary supply chain data that can save people's lives and, concurrently, in attracting the input of exponentially more valuable information by consumers about their personal experiences with food products (or products in general, for that matter) …."
But KDEs by themselves will not necessarily rid supply chains of the bullwhip effect. Without implementing a more social, fluid nature to the sharing of information in supply chains, KDEs may even increase the brittleness of one-up/one-down information sharing between database administrators, just more granularly so with "digital sand". For instance, industry standards for granular XML objects may be a bane … or a bon. It largely depends on the effectiveness of hierarchical administrative decision-making processes overseeing each data silo. Common point social networking holds forth a promise for implementing KDEs in a manner that overcomes the bullwhip effect.
But even with the most efficient and effective management processes, it is almost unimaginable to us that the first movement toward enterprise-consumer social networking will come from incumbent enterprise software systems. Sure, the first movement could potentially come from that direction, but we’ve just had too many experiences with enterprises and software vendors to put much faith in that actually happening. Conversely, we can much more easily imagine a first movement toward nextgen social from the "navigational search" demands of consumers. In our second tipping point blog we illustrated this point in some respect with Google Affiliate Networks. This time we are making our point with Google’s Knowledge Graph.
Navigational Search As A Business Model
Google's Knowledge Graph was announced this year as having being added to Google's search engine. Knowledge Graph is a semantic search system. Of course it’s not the only semantic search system. Bing incorporates semantic search. So do Ask.com and Wolfram Alpha. Siri provides a natural language user interface. But no matter what the semantic search engine, the search results are revealed as a list of ranked, relevant “answers” (or perhaps no answer at all because there isn’t one to give). Searching for real answers in real-time is still kind of a navigational mess either in commission or omission.
"For the semantic web to reach its full potential in the cloud, it must have access to more than just publicly available data sources. It must find a gateway into the closely-held, confidential and classified information that people consider to be their identity, that participants to complex supply chains consider to be confidential, and that governments classify as secret. Only with the empowerment of technological ‘data ownership’ in the hands of people, businesses, and governments will the Semantic Cloud make contact with a horizon of new, ‘blue ocean’ data." Cloud Computing: Billowing Toward Data Ownership - Part II.
Knowledge Graph is a "baby step" toward navigational search that provides a kind of Wikipedia "look and feel" experience designed to help users navigate more easily toward specific answers. Ever used the "I’m Feeling Lucky" button provided by Google? That button taps into Google's semantic search system to provide a navigational search resulting in a single result. This is an attempt to provide a purposeful effect instead of an exploratory effect to your search request. Yes, it's still a "hit or miss" artifice but - make no mistake - it is has been introduced for pushing forward navigational search as a business model. Google's business intent for navigational search is to discourage you from going to other search engines for your search needs. Knowledge Graph is designed to cut short a process of discovery which may take you away from Google to a competitive search engine. This move toward navigational search is exactly why we are proposing that now is the time for common point social networking. Without common point social networking, navigational search will largely remain a clever, albeit unsatisfactory, solution for what consumers really want. What consumers want is real-time, meaningful, trustworthy information about the products they buy or are interested in buying. As Amit Singhal, Senior Vice-President of Engineering at Google, says:
"We’re proud of our first baby step - the Knowledge Graph - which will enable us to make search more intelligent, moving us closer to the "Star Trek computer" that I've always dreamt of building. Enjoy your lifelong journey of discovery, made easier by Google Search, so you can spend less time searching and more time doing what you love."
Conclusion: Whole Chain Communications from Navigational Search
So much of the information that consumers desire about the products they buy - or may buy - is currently locked up in enterprise data silos. But the realistic prospects for common point social networking means that navigationally searching for enterprise data - as a business model - is no longer an impossible challenge akin to Starfleet Academy's Kobayashi Maru. The ultimate goal for Google's navigational search is essentially that of providing not just whole chain traceability but real-time, whole chain communications for consumers via their mobile devices. The ultimate goal for GS1's standards for granular whole chain traceability is to similarly provide opportunities for real-time, navigational search.
Google’s Knowledge Graph indeed represents the first step of a toddler. To fully develop a “Star Trek Enterprise computer” Google must drive nextgen social for enterprises by fostering the placement of common point social networking between the the bookends of navigational search and whole chain traceability. There is no other technology company better positioned or more highly motivated to do so. And we believe that it will. In backing the Wikidata Project, Google is already on a pathway to promoting common point social.
_______________________________
Authors:
 Steve Holcombe
Steve Holcombe
Pardalis Inc.
 Clive Boulton
Clive Boulton
Independent Product Designer for the Enterprise Cloud
LinkedIn Profile
_______________
Endnotes
Of relevance ...
Google Tests B2B Market With Google Shopping For Suppliers
30 Jan 2013 by Ginny Marvin
Search Engine Land
See also ...
Google Shopping for Suppliers - Beta
https://www.google.com/shopping/suppliers/

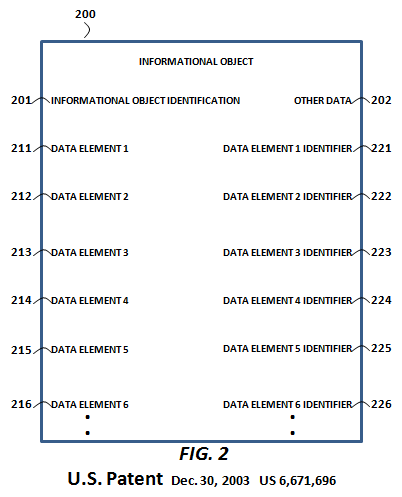 By contrast, CPA's methods provide for the selective sharing of informational objects (and their respective data elements) without the necessity of any collaboration. More specifically, CPA provides the foundational methods for the creation and versioning of immutable data elements at a single location by an end-user (or a machine). Those data elements are accessible, linkable and otherwise usable with meta-data authorizations. This is especially important when it comes to overcoming the fear factors to the sharing of enterprise data, or allowing for the semantic search of enterprise data. To the right is a representation from Pardalis' parent patent, "Informational object authoring and distribution system" (US Patent 6,671,696), of a granular, author-controlled, structured informational object around which CPA's methods revolve.
By contrast, CPA's methods provide for the selective sharing of informational objects (and their respective data elements) without the necessity of any collaboration. More specifically, CPA provides the foundational methods for the creation and versioning of immutable data elements at a single location by an end-user (or a machine). Those data elements are accessible, linkable and otherwise usable with meta-data authorizations. This is especially important when it comes to overcoming the fear factors to the sharing of enterprise data, or allowing for the semantic search of enterprise data. To the right is a representation from Pardalis' parent patent, "Informational object authoring and distribution system" (US Patent 6,671,696), of a granular, author-controlled, structured informational object around which CPA's methods revolve. Steve Holcombe
Steve Holcombe